The Meta AI support incident isn’t really a story about insecure AI. It’s a story about teams putting AI inside the security boundary instead of in front of it. The fix is architectural: treat AI as an untrusted communication interface, and route every sensitive decision through a layered stack of verification, authorization, and execution systems that don’t depend on the model being honest. Build assuming the AI can be manipulated, and design so that prompt injection or hallucination stays a mistake instead of becoming a security incident.
The reports about Meta’s AI-powered support systems should make every organization rushing to deploy AI agents and copilots stop and think.
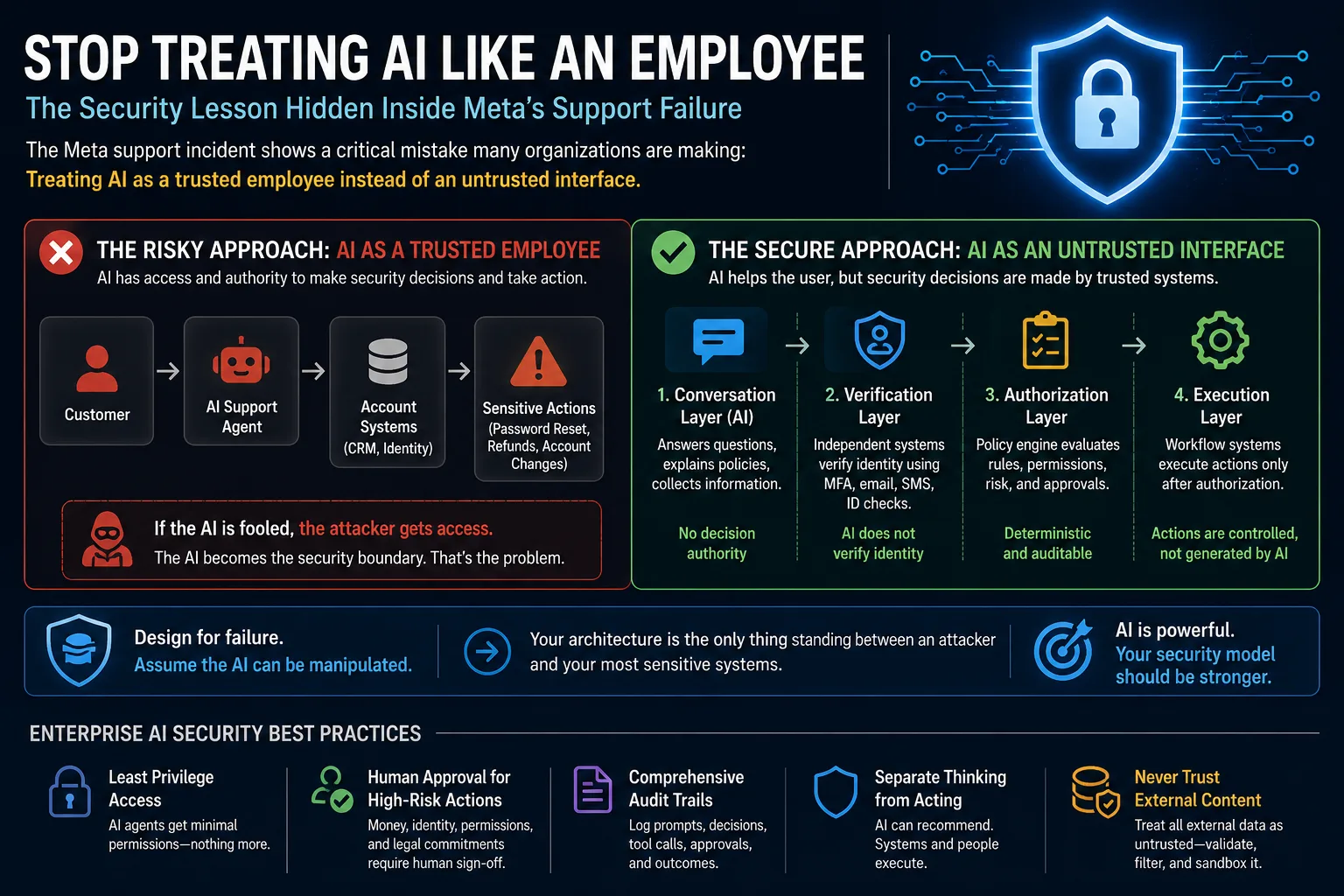
The lesson here isn’t that AI is insecure. The lesson is that a lot of organizations are making the same architectural mistake: they’re treating AI like a trusted employee instead of an untrusted interface.
That difference matters more than most security teams have realized yet.
The Wrong Question
When organizations start building AI support systems, the questions usually sound like this. How do we prevent prompt injection? How do we stop users from tricking the model? How do we make the AI follow instructions?
Every one of those questions assumes the AI can be trusted. It can’t.
Large language models are probabilistic. They interpret language, generate responses, and infer intent. They were never designed to make security decisions, and pretending otherwise is where the trouble starts.
The better question is simple. What happens if the AI gets manipulated?
If the answer is “nothing important,” your architecture is probably fine. If the answer is “the AI can reset passwords, unlock accounts, issue refunds, or change permissions,” then you’re trusting something that hasn’t earned it.
The Security Boundary Principle
Cybersecurity has run on one idea for decades: never trust user input.
AI changes what the interface looks like. It doesn’t change the principle. Every message sent to an AI system is untrusted input, which means the AI itself should never be the security boundary. The boundary belongs outside the model.
Take a common support scenario. A customer contacts support because they can’t get into their account. A lot of teams reach for a workflow that looks like this:
Customer → AI Support Agent → Account Recovery System
The AI takes in the information, evaluates the request, and performs the recovery. The flaw is right there in the diagram. An attacker only has to convince the AI.
A safer design adds the steps that actually matter:
Customer → AI Support Agent → Identity Verification Service → Authorization Engine → Recovery Workflow
The AI still gathers information, explains the policy, and walks the customer through the process. What it doesn’t do is decide whether the customer is who they say they are. That stays with a dedicated identity system, where it belongs.
AI Should Explain Security, Not Perform It
Think of the AI as a concierge.
A concierge can tell you where the conference room is, but can’t issue you a badge to get in. A concierge can explain how the refund process works, but can’t approve your refund. A concierge can walk you through password recovery, but doesn’t get to decide whether your password should be reset.
The AI’s job is communication. The security system’s job is authorization. The risk shows up when those two jobs blur together.
The Emerging Enterprise Pattern
The more mature AI deployments are converging on a layered approach.
Layer 1: Conversation. The AI talks to the customer. It answers questions, summarizes information, explains policies, and collects the details that are needed. It cannot execute sensitive actions.
Layer 2: Verification. Dedicated identity systems handle multi-factor authentication, device verification, identity checks, and fraud detection. The AI plays no part in the decision.
Layer 3: Authorization. Policy engines decide who can do what, under what conditions, and what approvals are required. These rules are deterministic and auditable.
Layer 4: Execution. Workflow systems carry out password resets, account recovery, billing adjustments, and membership changes. Only after verification and authorization are done.
The Mindset Shift
For years, organizations have poured effort into making systems trustworthy, with AI, the goal needs to be different.
The old question was “how do we make the model safe?” The question worth asking now is “how do we make the architecture safe even when the model fails?”
That sounds subtle. It isn’t. No competent security team assumes every employee makes perfect decisions, that every email is legitimate, or that every user is honest. There’s no reason to extend your AI a level of trust you’d never extend to a person.
Designing for Failure
The strongest AI security architectures start from the assumption that compromise is possible.
Prompt injection can succeed, social engineering can succeed. The model can lose the thread of the conversation. The model can hallucinate. None of that should be allowed to cause real damage.
The point was never to build a perfect AI. The point is to build a system where an AI mistake stays a mistake and never becomes a security incident.
The Future of AI Governance
The organizations that do well with AI over the next decade won’t be the ones with the most powerful models. They’ll be the ones with the strongest governance. (For a sector-specific take on what proportional governance actually looks like, see AI Governance for Canadian Nonprofits.)
In practice that means least privilege access, independent verification systems, human approval for high-risk actions, real audit trails, and a clear line between communication and authorization.
The Meta incident won’t be the last AI security story this year, but it might be one of the more useful ones, because it’s a reminder of what AI actually is. Not a trusted employee. A powerful interface sitting between your users and systems that still need the same security controls they always did.
Frequently Asked Questions
Why is AI an untrusted interface and not a trusted employee?
Large language models are probabilistic. They interpret language, infer intent, and generate plausible responses. They were not designed to make security decisions, and prompt injection, social engineering, and hallucination all give an attacker ways to manipulate model output. Treating any input arriving via an AI surface as untrusted is the same principle that has governed web security for decades; the interface has changed, the principle hasn’t.
What was the lesson from the Meta support AI incident?
The Meta support incident wasn’t really an “AI is broken” story. It was a story about putting AI inside the security boundary, with authority to make decisions that should have lived in independent verification and authorization systems. The architectural fix is to move sensitive decisions out of the model entirely.
What is the layered architecture for safe AI support systems?
Four layers, each with one job, conversation: the AI talks to the user and collects information; it cannot act on sensitive systems, verification: dedicated identity systems handle MFA, device checks, and fraud detection, authorization: policy engines decide what actions are allowed and what approvals are required, deterministically and auditably. Execution: workflow systems perform the actual change (password reset, refund, account recovery) only after verification and authorization are complete.
How do you protect against prompt injection in production?
You don’t try to make prompt injection impossible. You make it harmless. Assume it will succeed sometimes, then design so a compromised model output cannot trigger a sensitive action without passing through an independent verification system, a deterministic authorization engine, and (for high-risk operations) human approval. Input filtering and prompt hardening are useful defence-in-depth, but they should never be the only line.
What are the enterprise best practices for AI security?
Five hold up across most deployments: least-privilege access for AI agents (only the permissions the task actually needs); human approval for high-risk actions (money, identity, permissions, legal commitments); comprehensive audit trails (logs of prompts, decisions, tool calls, approvals, outcomes); separation of thinking from acting (AI can recommend, dedicated systems execute); and never trusting external content (treat every retrieved document, web page, or tool output as untrusted input and filter and sandbox it).
Should AI ever execute sensitive actions on its own?
For low-stakes, reversible actions with strong audit trails, yes. That’s how agentic systems get useful. For high-stakes actions (password resets, financial transactions, permission changes, account recovery, legal commitments), the answer is no. Those decisions should always flow through independent verification, deterministic authorization, and. Where the blast radius justifies it. Human approval. The goal is not zero AI autonomy; it’s autonomy proportional to blast radius.
What’s the single most important mindset shift for AI security?
Stop asking “how do we make the model safe?” and start asking “how do we make the architecture safe even when the model fails?” That single reframing pushes you toward defence-in-depth, independent verification, deterministic authorization, and least privilege. The controls that already work for every other untrusted interface in your stack.